Compression Statistique � Contexte Fini
Fabrice Bellard
Il s'agit de r�aliser un compresseur/d�compresseur de donn�es sans perte.
Les priorit�s ont �t� d�finies ainsi :
- taux de compression tr�s important ;
- grande vitesse ;
- faible quantit� de m�moire requise ;
- facilit� d'interfa�age des routines de compression.
Les m�thodes classiques fond�es sur les dictionnaires du type Ziv-Lempel sont
d�pass�es en terme de taux de compression par les m�thodes statistiques �
contexte fini [1]. Nous avons donc choisi une de ces derni�res.
L'algorithme est mono-passe, donc il doit s'adapter aux donn�es de fa�on
dynamique. Le principe du compresseur est le suivant:
Il s'agit de pr�dire le symbole suivant d'un fichier en utilisant un
contexte constitu� au plus des 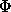 symboles pr�c�dents (
symboles pr�c�dents (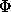 est
un nombre positif arbitraire fix�). On conserve donc en m�moire une table
T de tous les contextes d�j� rencontr�s dans le fichier. Lorsque le
symbole a �t� cod�, on met � jour T. Notons que le d�compresseur
fonctionne de fa�on exactement sym�trique.
est
un nombre positif arbitraire fix�). On conserve donc en m�moire une table
T de tous les contextes d�j� rencontr�s dans le fichier. Lorsque le
symbole a �t� cod�, on met � jour T. Notons que le d�compresseur
fonctionne de fa�on exactement sym�trique.
Pour le codage du symbole courant, on commence par chercher dans T le plus
long contexte d�j� recontr� coïncidant avec le contexte courant. On a
not� pour chaque contexte de T une liste L des fr�quences de tous les
symboles le suivant. Plusieurs cas se pr�sentent :
- Aucun contexte n'a �t� trouv�. Le symbole est cod� tel quel.
- Le symbole se trouve dans la liste L. On le code en utilisant peu
de bits si la fr�quence du symbole a �t� importante.
- Le symbole n'est pas pr�sent dans L. On envoie un code sp�cial
ESCAPE et on recherche dans T un contexte plus court.
Ce n'est pas la partie principale du projet, et elle ne sera pas d�crite
ici. On s'attachera � faire un programme rappelant gzip ou
compress et pouvant facilement �tre �tendu par ajout d'autres m�thodes de
compression, de cryptage, ou de d�tection et correction d'erreurs.
En fait l'algorithme choisi est un peu plus compliqu� que celui d�crit en
1.2. En voici les d�tails.
Nous utilisons un codeur arithm�tique pour coder les symboles. Si un
symbole a une probabilit� d'apparition p, nous le codons en utilisant en
moyenne 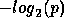 bits.
bits.
Nous pr�voyions au d�part d'utiliser un codeur arithm�tique binaire
fonctionnant par approximations, ce qui aurait donn� une vitesse plus grande
[2]. Malheureusement, son utilisation est emp�ch�e par le m�canisme
d'exclusion des symboles. Notre codeur est donc du type tr�s classique
bit plus follow et utilise 2 multiplications et 2 divisons enti�res par
symbole cod�. Une description pr�cise de ce codeur sort du cadre de ce
rapport.
Nous avons int�gr� au codeur et au d�codeur des buffers pour acc�l�rer les
entr�es/sorties.
Les tests de vitesse d�montrent que le codeur ne mobilise pas plus de 15%
du temps total de compression, ce qui est satisfaisant.
Lorsqu'on a �t� oblig� d'envoyer des codes ESCAPE, on peut
exclure de la liste L des symboles associ�s au contexte courant ceux qui
ont d�j� �t� rencontr�s dans les contextes de longueur sup�rieure. En effet,
la g�n�ration de ESCAPE implique qu'aucun des symboles des contextes
de longueur sup�rieure ne vient apr�s le contexte courant. Cette
am�lioration augmente le taux de compression d'environ 5% [1].
Etant donn� notre cahier des charges, nous devons l'incorporer. Cela pose un
grave probl�me: il est quasiment impossible d'utiliser une structure autre
qu'une liste cha�n�e pour stocker la liste des symboles associ�s � un
contexte si on veut permettre le m�canisme d'exclusion, tout en facilitant
les calculs pour le codage du symbole courant. Etant donn� que l'on a 256
symboles diff�rents, le temps de parcours de la liste n'est pas n�gligeable.
Le syst�me d'exclusion utilise un tableau � 256 entr�es. L'id�e de d�part
consiste � initialiser ce tableau � FALSE, puis mettre � TRUE
toutes les entr�es correspondant aux num�ros de symboles exclus. Cela
pr�sente un d�faut: il faut initialiser ce tableau avant chaque nouveau
codage de symbole, et le temps pris n'est pas n�gligeable.
Une m�thode consiste � utiliser un tableau d'entiers, et � caract�riser
l'exclusion d'un symbole par la mise dans l'entr�e du tableau correspondante
d'un certain code. Si on change ce code � chaque nouveau symbole (par
incr�mentation par exemple), on �vite l'�tape d'initialisation, ou du moins
on la rend moins fr�quente.
L'utilisation du codeur/d�codeur arithm�tique n�cessite le partitionnement
de l'intervalle 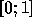 en sous-intervalles de mesure
en sous-intervalles de mesure 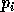 o�
o� 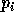 est la
probabilit� d'apparition du symbole
est la
probabilit� d'apparition du symbole 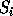 . Plus pr�cis�ment, pour coder le
symbole
. Plus pr�cis�ment, pour coder le
symbole 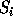 , il suffit de connaitre
, il suffit de connaitre 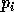 et
et 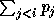 . Les
probabilit�s sont transmises au codeur sous la forme fractionnaire
. Les
probabilit�s sont transmises au codeur sous la forme fractionnaire 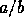 avec
avec 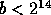 .
.
Le codage d'un symbole n�cessite donc un parcours lin�aire de L o� l'on
additionne les fr�quences des symboles jusqu'� la rencontre du symbole �
coder. Notons que l'on num�rote ici les symboles suivant leur ordre
d'apparition dans la liste car il suffit que compresseur et d�compresseur
utilisent la m�me convention.
On incr�mente ensuite la fr�quence associ�e au symbole cod� et l'on teste
s'il faut renormaliser le contexte.
Pour des raisons d'efficacit�, on peut inclure dans le contexte la somme
totale des fr�quences des symboles associ�s, c, et le nombre de
symboles, t. On �vite ainsi un parcours global de la liste L. Notons que
ces variables sont inutiles dans le cas o� certains symboles doivent �tre
exclus.
Quelle est la probabilit� � affecter � ESCAPE ? Il n'existe pas de
m�thode optimale. Nous avons choisi pour des questions de vitesse et de
simplicit� une probabilit� �gale � 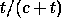 . Elle correspond � la m�thode
PPMC d�crite dans [1].
. Elle correspond � la m�thode
PPMC d�crite dans [1].
Pour des questions d'encombrement m�moire, la fr�quence de chaque symbole de
L est cod�e sur 1 octet. D'autre part, nos routines de codage arithm�tique
imposent une borne sup�rieure sur la valeur du d�nominateur des
probabilit�s. Nous devons donc renormaliser les contextes de temps en
temps en divisant par exemple les fr�quences par 2. Les symboles atteignant
une fr�quence nulle sont exclus du contexte.
Ce dernier point augmente l�g�rement le taux de compression en permettant
une adaption plus rapide.
On utilise un symbole sp�cial pour coder la fin de fichier. Cela permet de
rendre le compresseur r�ellement monopasse. D'autres caract�res sp�ciaux
peuvent �tre ajout�s pour permettre par exemple un contr�le de flux. Ils
sont cod�s comme s'ils n'apparaissaient dans aucun contexte.
La taille de la table des contextes est limit�e par la m�moire allou�e au
compresseur. On a choisi ici une approche originale consistant � �liminer
les contextes les moins r�cemment utilis�s [3]. Les contextes sont
donc rang�s dans une liste doublement cha�n�e permettant les 2 op�rations de
base:
- remettre un contexte en t�te de la liste lorsqu'il est utilis� pour le
codage d'un symbole ;
- effacer le dernier contexte de la liste si l'on manque de m�moire.
Cette structure ne permet pas d'utiliser facilement un arbre ou un trie pour
rechercher les contextes. On utilise donc une table de hachage avec gestion
des collisions par une liste simplement cha�n�e. Elle aurait d� �tre en fait
doublement cha�n�e pour permettre l'effacement rapide d'un contexte. Comme
les contraintes m�moire sont s�v�res, nous avons pr�f�r� supposer que la
table de hachage est assez grande pour limiter le nombre de collisions.
La liste des fr�quences des symboles est une liste simplement cha�n�e
contenant le num�ro du symbole et sa fr�quence.
Etant donn�es les contraintes de vitesse et de m�moire, un appel �
l'allocateur m�moire standard du C est proscrit.
Nous aurions pu choisir comme dans [3] d'allouer un heap (zone
m�moire) pour les structures de taille fixe associ�es aux contextes, et un
autre pour stocker les �l�ments des listes de symboles associ�s aux contextes.
Cette solution n'est pas bonne car elle n'utilise pas la m�moire de fa�on
efficace: il faudrait connaitre a priori le rapport entre l'occupation
m�moire du premier heap et du second, ce qui d�pend du fichier compress�.
Notre compresseur n'utilise donc qu'un seul heap, de taille param�trable
suivant la m�moire disponible et le taux de compression voulu. Ce heap est
structur� en noeuds de taille fixe. On maintient constamment une
liste simplement cha�n�e des noeuds libres pour l'allocation et la
d�sallocation m�moire. Dans un noeud on stocke soit un contexte, soit un
certain nombre d'�l�ments de la liste des symboles associ�s aux contextes.
L'exp�rience montre que c'est un excellent compromis.
L'impl�mentation de l'algorithme doit �tre soign�e car certaines proc�dures
sont ex�cut�es beaucoup de fois par symbole. On a veill� � limiter au
maximum le nombre d'acc�s m�moire car c'est ce qui prend le plus de temps
sur les ordinateurs modernes. De plus, en conservant l'adjacence des donn�es
corr�l�es, on favorise l'utilisation du cache interne du micro-processeur.
Les seules suppositions faites au niveau du hardware sont: int cod�
sur 32 bits, short sur 16 bits, et char sur 8 bits.
Voir les fichiers arith_e.c et arith_d.c.
On notera l'utilisation d'une fonction pass�e en argument aux fonctions de
codage qui sert � �crire ou lire un buffer sur disque (ou ailleurs). Ainsi
les routines de codages sont isol�es des fonctions d'entr�e/sortie.
Voir le fichier ppm.c.
Tout l'algorithme s'articule autour de la structure NODE . On remarque
l'utilisation massive d'index 16 bits � la place de pointeurs. Cela
permet d'�conomiser de la pr�cieuse m�moire. La structure NODE a ainsi
une taille de 16 octets pour acc�l�rer l'acc�s par les index.
Lors des statistiques, on a remarqu� que les contextes contenant une liste de
1 ou 2 symboles sont de loin les plus courants (80% des contextes en
moyenne). On a donc int�r�t � les g�rer de fa�on sp�cifique, ce qui explique
la structure un peu compliqu�e n�cessaire pour g�rer les contextes.
La fonction de hachage est du type: 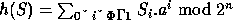 o� a=63 et n=14. Au niveau th�orique elle ne semble
pas bonne mais les tests montrent qu'elle se comporte plut�t bien et surtout
qu'elle se calcule tr�s vite. Sa formule s'exprime aussi de fa�on r�curente
ce qui permet de la calculer partiellement pour chaque longueur de contexte
� chercher.
o� a=63 et n=14. Au niveau th�orique elle ne semble
pas bonne mais les tests montrent qu'elle se comporte plut�t bien et surtout
qu'elle se calcule tr�s vite. Sa formule s'exprime aussi de fa�on r�curente
ce qui permet de la calculer partiellement pour chaque longueur de contexte
� chercher.
Voir les fichiers stat.c, testcode.c, et getopt.c.
Le fichier de commande stat_test permet de tester la compression sur
un fichier donn� en v�rifiant le checksum. Une routine de calcul de
CRC 32 bits aurait pu �tre incluse.
Nous avons r�alis� les tests sur les fichiers du Calgary Text
Compression Corpus sur un 486DX2/66 sous Linux. On a compar� les
compresseurs suivants:
- gzip, en mode compression maximale.
- stat, longueur maximum des contextes
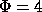 , nombre de noeuds
N=40000 (640k de m�moire)
, nombre de noeuds
N=40000 (640k de m�moire)
- stat,
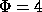 , N=8000 (128k)
, N=8000 (128k)
Les r�sultats sont r�sum�s dans le tableau 1
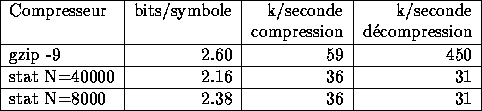
Table 1: R�sultats des tests
stat est seulement 2 fois plus lent que gzip en compression.
C'est au niveau de la d�compression qu'il est tr�s nettement distanc�. En
effet, la m�thode utilis�e est totalement sym�trique, alors qu'un
d�compresseur de type LZ77 est tr�s simple et tr�s rapide.
Notre syst�me de gestion de m�moire est tr�s efficace, puisque m�me avec
aussi peu de m�moire que 128k (soit moins que gzip en compression)
nous avons des gains significatifs.
Des tests plus pouss�s non mentionn�s ici montrent que sur les fichiers
textes stat atteint des vitesses importantes et compresse beaucoup
mieux (10% environ) que n'importe quel autre compresseur Ziv-Lempel. En
revanche sur les fichiers binaires il peut �tre tr�s lent, et les gains par
rapport � Ziv-Lempel sont plus faibles. Cette lenteur provient de
l'utilisation du m�canisme d'exclusion qui impose de longs parcours de
listes cha�n�es.
En revanche, grace � son syst�me de gestion de m�moire efficace, il bat les
compresseurs statistiques standards comme PPMC grace � ses facult�s "d'oubli
adaptif" des contextes les moins utilis�s.
Il reste encore bien des choses � am�liorer. Ce compresseur ne repr�sente
qu'une �tape dans la progression des m�thodes statistiques. Nos derni�res
�tudes montrent qu'il est possible de faire un compresseur/d�compresseur
beaucoup plus rapide que gzip tout en augmentant encore les gains (de
quelques pourcents) en augmentant seulement l�g�rement l'encombrement
m�moire. Sa description sort du cadre de ce rapport.
Au niveau des fichiers binaires, nos tests ont montr� qu'il �tait possible
de faire des "pr�-processeurs" adapt�s au langage machine d'un ordinateur
donn� qui pr�sentent les donn�es au compresseur sous un forme plus facilement
compressible.
Pour les textes, on pourrait r�aliser des pr�-processeurs r�alisant par
exemple une pr�diction de l'indentation des fichiers, ou de la justification
des paragraphes, chose que les compresseurs � contexte fini ou �
dictionnaire ne peuvent pas faire.
Ce projet est un bon exercice de programmation puisqu'il utilise beaucoup de
structures de donn�es imbriqu�es. Ces derni�res, ainsi que les diff�rents
algorithmes n'ont pas �t� choisi au hasard mais r�sultent bien d'une
recherche de compromis entre les diff�rents points du cahier des charges. On
a essay� ici de retracer la d�marche suivie.
References
- 1
- Bell, Cleary, Witten, Text Compression, 1990.
- 2
- Raita, Teuhola, Predictive text compression by
hashing, 1987.
- 3
- Harri Hirvola, HA Archiver 0.98 , 1993.
Sun Dec 10 18:42:24 MET 1995
Fabrice Bellard ([email protected])